import pandas as pd22 Pandas Basics Part 3 — Workbook
22.1 Dataset
22.1.1 The Pudding’s Film Dialogue Data
The dataset that we’re working with in this lesson is taken from Hannah Andersen and Matt Daniels’s Pudding essay, “Film Dialogue from 2,000 screenplays, Broken Down by Gender and Age”. The dataset provides information about 2,000 films from 1925 to 2015, including characters’ names, genders, ages, how many words each character spoke in each film, the release year of each film, and how much money the film grossed. They included character gender information because they wanted to contribute data to a broader conversation about how “white men dominate movie roles.”
22.2 Import Pandas
To use the Pandas library, we first need to import it.
22.3 Change Display Settings
By default, Pandas will display 60 rows and 20 columns. I often change Pandas’ default display settings to show more rows or columns.
pd.options.display.max_rows = 20022.4 Get Data
film_df = pd.read_csv('../data/Pudding/Pudding-Film-Dialogue-Clean.csv', delimiter=",", encoding='utf-8')This creates a Pandas DataFrame object — often abbreviated as df, e.g., slave_voyages_df. A DataFrame looks and acts a lot like a spreadsheet. But it has special powers and functions that we will discuss in the next few lessons.
22.5 Overview
To look at a random n number of rows in a DataFrame, we can use a method called .sample().
film_df.sample(10)Generate information about all the columns in the data
film_df.info()Just like Python has different data types, Pandas has different data types, too. These data types are automatically assigned to columns when we read in a CSV file. We can check these Pandas data types with the .dtypes method.
| Pandas Data Type | Explanation |
|---|---|
object |
string |
float64 |
float |
int64 |
integer |
datetime64 |
date time |
Make a histogram of the DataFrame
film_df.hist(figsize=(10,10))Generate descriptive statistics for all the columns in the data
film_df.describe(include='all')22.5.1 ❓ What patterns or outliers do you notice?
22.6 Drop Rows
film_df[film_df['age'] > 100]If you want to double check, you can examine the data that the Pudding shared here (you can control + F to search for specific characters).
film_df = film_df.drop(film_df[film_df['age'] > 100].index) film_dffilm_df[film_df['age'] > 100]| title | release_year | character | gender | words | proportion_of_dialogue | age | gross | script_id |
|---|
22.7 Rename Columns
film_df = film_df.rename(columns={'imdb_character_name': 'character', 'year': 'release_year'})film_df.head()22.8 Filter
Group work!
Find a specific film that you’re intersted and then filter the DataFrame for only rows relevant to that film.
If you want to search for films by decade and genre, you can search the with the Pudding’s handy data viz here.
film_filter = ...If you want to sort by characters who speak the most, feel free to add .sort_values(by='words', ascending=False)
film_df[film_filter]Now pick a character from this film (or another character) and filter the DataFrame by character.
character_filter = ...film_df[character_filter]22.8.1 ❓ How does this data align with your experience/knowledge of the film?
22.8.2 ❓ How do these specific examples influence your thoughts about the data collection and categorization process? What would you have done differently (if anything)?
22.9 Sort Values
Group work!
Sort the DataFrame from the character who has the highest proportion_of_dialogue to the lowest. Then examine the first 20 rows with .head(20) or [:20].
film_df...Sort the DataFrame from the character who has the lowest proportion_of_dialogue to the highest. Then examine the first 20 rows with .head(20) or [:20].
film_df...Sort the DataFrame from the character who speaks the least number of words to the character who speaks the most number of words. Then examine the first 20 rows with .head(20) or [:20].
film_df...22.9.1 ❓ What patterns do you notice here? What surprises you or doesn’t surprise you?
22.10 Groupby
Group by film and then calculate the sum total for every column.
film_df.groupby...Group by film, isolate the words column, and then calculate the sum total for every column.
film_df.groupby...Group by film AND gender, isolate the column words, and then calculate the sum total for every column.
Note: Remember that to group by multiple columns, you need to put the column names in square brackets [].
film_df.groupby...22.11 Filter, Then Groupby
Group work!
Filter the DataFrame for only characters labeled as woman
women_filter = film_df['gender'] == 'woman'women_film_df = film_df[women_filter]Filter the DataFrame for only characters labeled as man
men_filter = film_df['gender'] == 'man'men_film_df = film_df[men_filter]Now group women_film_df by film, isolate the words column, and sum the words spoken by women.
women_film_df.groupby('title')['words'].sum()title
(500) Days of Summer 5738
10 Things I Hate About You 8992
12 Years a Slave 3452
12 and Holding 5324
127 Hours 809
...
Zero Effect 2216
Zerophilia 4612
Zodiac 1421
eXistenZ 3752
xXx 998
Name: words, Length: 1940, dtype: int64Assign this Series to a new variable women_by_film
women_by_film = women_film_df.groupby('title')['words'].sum()Using the same construction, make a new another new variable men_by_film
men_by_film = men_film_df.groupby('title')['words'].sum()Sort women_by_film from the film with the most words to the film with the least words. Then examine the top 20 values.
women_by_film.sort_values(ascending=False)[:20]Assign this sorted list of movies to the variable top20_women
top20_women = women_by_film.sort_values(ascending=False)[:20]Using the same construction, make a new variable top20_men
top20_men = men_by_film.sort_values(ascending=False)[:20]22.11.1 ❓ What patterns do you notice here? What surprises you or doesn’t surprise you?
22.12 Saving Plots
Group work!
Make a bar chart of top20_women. Give the chart a title, and specify a color.
top20_women.plot(kind='bar')To save the plot, you can use ax.figure.savefig() and the name of the file in quotation marks.
ax = top20_women.plot(kind='bar')
ax.figure.savefig('top20_women.png')Look in the file browser on the left and double click the PNG file. How does it look? Uh oh!
Sometimes parts of a plot will get cut off when you save it. To fix this issue, you can use a function from the Matplotlib library called plt.tight_layout(), which will adjust the plot before you save it.
To use this function, you need to import matplotlib.pyplot as plt.
import matplotlib.pyplot as plt
ax = top20_women.plot(kind='bar')
plt.tight_layout()
ax.figure.savefig('top20_women.png')22.13 Scatter Plots and Line Plots
Let’s make a scatter plot that shows how many words women and men speak based on their age.
women_film_df.groupby('age')['words'].sum().reset_index()women_age_words = women_film_df.groupby('age')['words'].sum().reset_index()men_age_words = men_film_df.groupby('age')['words'].sum().reset_index()ax = women_age_words.plot(kind='scatter', x='age', y='words', color='red')
men_age_words.plot(ax=ax, kind='scatter', x='age', y='words', color='blue')<matplotlib.axes._subplots.AxesSubplot at 0x7fe2bc8383d0>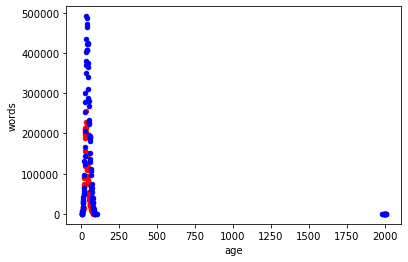
Now let’s make a line plot of the exact same data. Copy and paste the code in the cell above and change it to produce a line plot instead of a scatter plot.
Group work!
# Your code here
# Your code hereIf there is anything wrong, please open an issue on GitHub or email f.pianzola@rug.nl